
High-energy electromagnetic radiation or x-raying your architecture
The next step is to setup CloudWatch logs and start using X-Ray to make the debugging and tracing of what is going on with nodes of your AWS architecture easier. To utilize X-Ray you will need to use SDK or to set up out of the box X-Ray support for Lambdas and API gateway.
- Lambda functions should have ‘Enable AWS X-Ray’ to be selected to be analyzed by the X-Ray.
- For container microservices the SDK has to be utilized to be picked up by the X-Ray tracer engine.
- For API Gateway X-Ray Tracing has to be enabled and a set of sampling rules has to determined.
When AWS SDK is used it takes the responsibility of sending the peace of JSON to X-Ray daemon which produces it to XRay API for further service map visualization.
By looking at the image of the pretty small application below you can understand how complex it can be detected the problem without an ability to debug it just in microservices execution chain to. You can imagine the level of complexity to trace the problem within multiple chains.
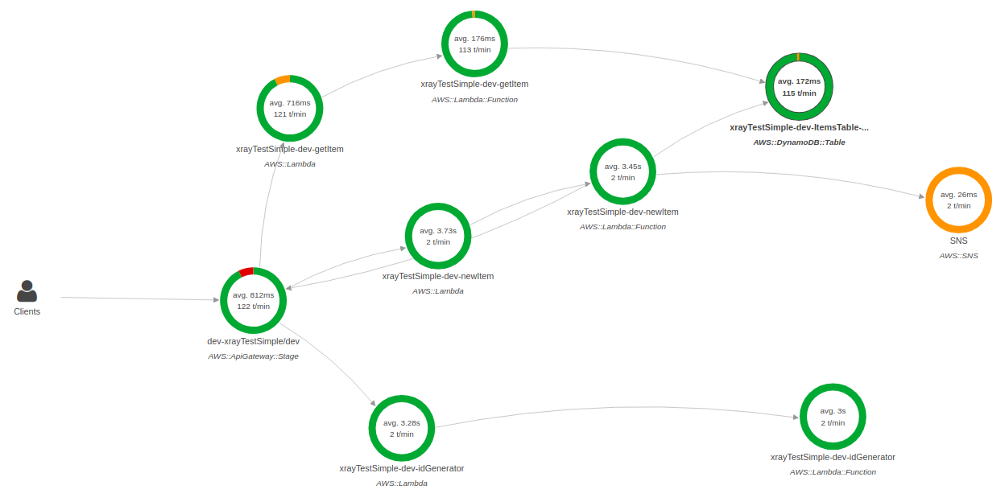
So, basically X-Ray can be used as a kind of helper to the log which is used to construct the execution map and trace errors and grab information about performance, efficiency of the architecture and lambda execution time itself.
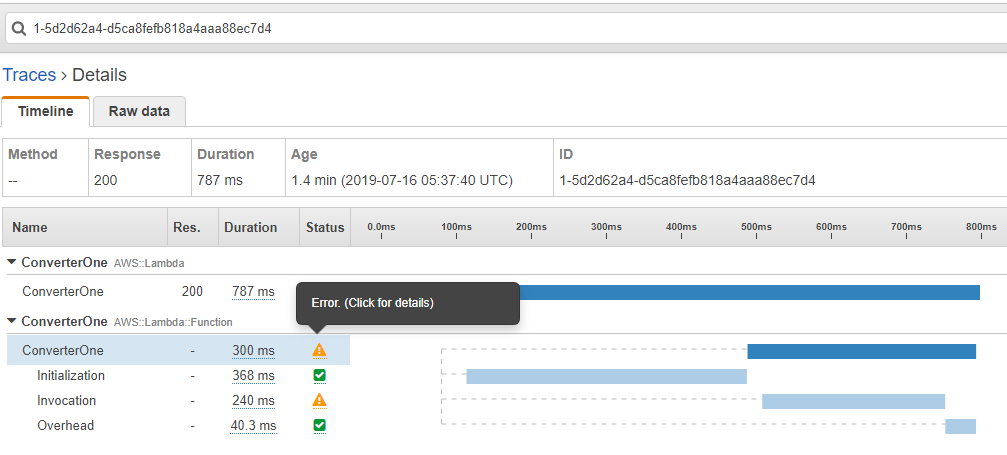
By looking at the image below you can get an understanding of where the problem comes from and what it is about.
Serverless authentication
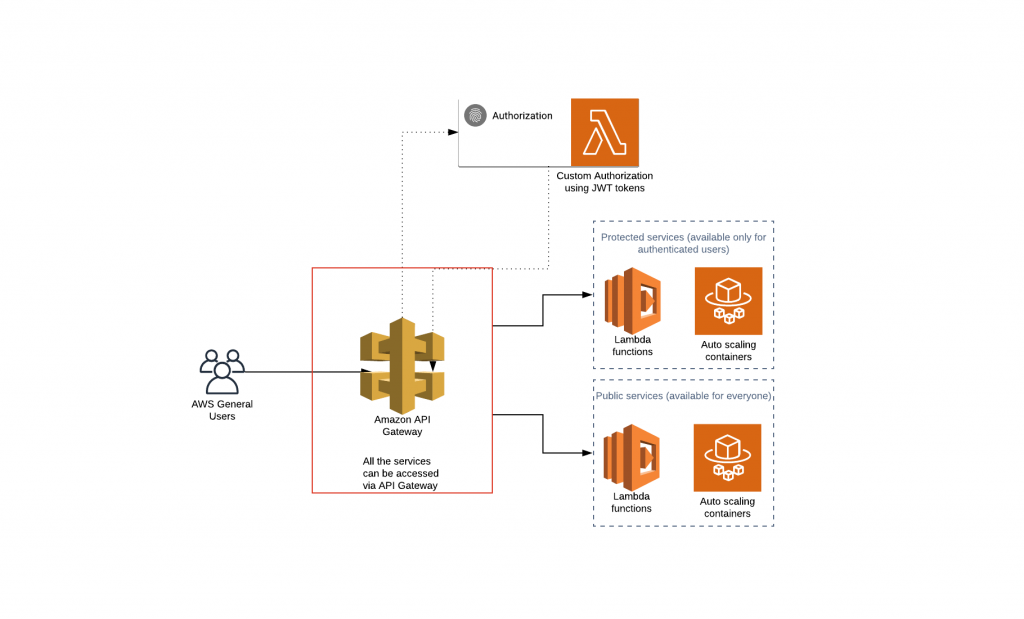
Almost all applications require an authentication mechanism. It can be different such as Basic authentication, OAuth authentication, token authentication, etc. In the world of serverless, some authentication types cannot be used due to the nature of serverless architecture which denies stateful types of authentication. There are various ways of dealing with it, however the most popular ways of doing authentication is to use Auth0 which is a cloud based platform for universal authentication & authorization for web and mobile applications. Apart of that AWS authorizers can be utilized. There are two types of authorizers provided by AWS platform using Cognito user pools which is a recommended option for mobile applications and custom authorizers using JWT (JSON Web Tokens) tokens. A great variety of developers use custom authorizers to protect there microservices sitting behind API Gateway. The idea behind it is that JWT are a compact and self-contained way for securely transmitting information and represent claims between parties as a JSON object. Simplified version of that process can be seen on the diagram presented below.
Testing in serverless
We all know how important it is to have at least unit tests. And you can have even more benefits by having integration tests as well. Some of you might have heard about companies which code is automatically delivered to prod with any manual testing being involved. The answer to the obvious question ‘how it is possible to be?’’ – is they have all tests set up. Some big companies such as Amazon or Netflix have thousands deployments a day. I am not going to discuss obvious benefits of using it in this document, especially in complex microservices architectures, so let’s come back to the topic.
Most of you have a solid work experience with unit tests for monolith application, but how it can be done when you code doesn’t have a server (technically it has, but it doesn’t have some known, managed by you place where it is executed)? AWS provides an awesome interaction between its build and deployment services (CodeBuild and CodePipeline) and running test actions. CodePipeline can orchestrate the Build, Test, and Deployment of your application every time there is a change to your code. Because of it in-built integration with other AWS services you can run any of your tests at any stage to make sure that the deploying package will pass all tests prior to the deployment.
Another great thing is that SAM which is used for Lambda deployments has in-built support for pre-traffic and post-traffic hooks to run test functions to verify that the newly deployed code is configured correctly and your application operates as expected and ability to roll back the deployment if CloudWatch alarms are triggered in the case of fail. Besides that SAM has a unique feature which allows developers to test their code locally before it even goes in any prod by using the SAM local invoke command to manually test their code by running Lambda functions locally. There is even a support for step-through debugging (links for doing it for .net and node.js development will be presented below).
Due to the fact that a separate document can be created for the whole testing part, I’ve decided to provide a set of useful links which can explain how you developers can test their code and how it can be tested as a part of the CICD.
Serverless best practises
As every application, serverless approach has its own set of recommendations which should be followed to prevent significant headache of debugging, tracing, maintainability, etc. Most of us are familiar with the design patterns (I hope that most of us) which are commonly used in everyday life, so servereless is not a rocket science which completely turned the world upside down. On the contrary, it is built on pillars of existing design patterns, aggregation of certain good dev practices and highly depend on the certain concepts such as SoC (separation of concerns) design principle and EDA (event driven architecture). In general these ideas can be aggregated to form the list of recommendations presented below:
- Each function should do only one thing (most of you may know it as the single responsibility principle),
- Functions should not call other functions. This can blow someone’s brain but that is really important gotcha in adopting serverless approach. It only sounds odd from the first perspective but this is just a different model of architecture. So, basically, it is not recommended because by doing it you double, triple or even quadruple your cost (depending on how many sub calls are). Moreover, the entire debugging process becomes more complex. Besides that it sets back the value of the isolation of your functions declared in the previous option. DevOps (let’s try to forget about separation between developers and operational, because you should become both if you want to be the efficient serverless practitioner) should change the model of their thinking from being get used to monolithic straightforward communication between modules and direct function calls to a total separation of nodes in the architecture map. Modules are no longer allowed to directly call each other or even know about each other. Functions should produce messages, push data to a data store or queue, communicate via event bus, etc. which in turn should trigger another function or be picked up by the subscribed function.
- Use as few libraries in your functions as possible. That is the particularly interesting statement because many developers may argue with that and they will be right from some point of view. However, the reason to reduce the amount of libraries is mainly because functions have cold starts and warm starts. This is not that important for scripting languages like python or javascript, but .net core or java will suffer a lot on a cold start. Furthermore, cold starts are impacted by a number of things and both the size of the package and the number of libraries that need to be instantiated are a part of it. Although, it needs to be noted that generally, compiled code runs faster than interpreted code of scripting languages due to the fact that they are first converted native machine code. Nevertheless, cold start needs to be significantly taken into account considering the time limit of the lambda execution.
- Use DDD (Domain-driven design). All your microservices should have an architectural style with a clear bounded context. Entire architecture has to be designed in a way that context within which a model applies is explicitly defined. You have to always perfectly analyze your domains and define bounded contexts. Use domain events to explicitly for interaction within your domain (SNS can be used to publish messages). Considering this you no longer need to scale up dependencies (see previous best practice) in your services since they will be dedicated for certain work and delegate the work to other services once it is needed. One side affect benefit of doing it for the serverless is that it helps to reduce the size of the microservice package which affects the cold start of the Lambda function (if you use). You can read more about it here.
- Avoid using connection based services. In my some critical cases in can be used, but the number of exceptional situations when it is allowed is strictly limited. Most of the time it is related with the cases when you have a monolithic architecture of the code and database and cannot redesign dependencies and move out logic between microservices in a reasonable amount of time or when you have to load data from some third party database. It can sound hard, especially for web application specialists who got used to use monolithic architecture for their needs. However, it makes sense when you think deeply about the entire serverless architecture, limitations of execution time and memory. Moreover, connections use undetermined time to manage connections, change states, close connections, release memory, etc. In general it creates a significantly adds up I/O wait into the cold start of the function which can end up in unexpected performance degradation (when it is a cold start). Nevertheless, this rule doesn’t apply to serverless storage services such as DynamoDB and Aurora (serverless RDS engine based on MySQL or PostgreSQL) essentially due to the fact that their connections are different. You no longer have persistent connections from the client to a database server. Basically the difference is in how the data are read/write to/from the storage. With the RDS you have to open a connection to the engine and keep it open while the application/request/transaction is in use. However, when you execute a DynamoDB query or scan it works as an HTTP request. Communication with the DynamoDB should treated as a communication with the web service rather than database. So, remember if you realize that your function requires the connection and you cannot move storage of your microservice into DynamoDB or Aurora or store it in S3, then think about using auto scaling microservice container (AWS ECS or AWS Fargate can be used for this purpose) which will be more suitable for that job.
- Use messages and queues. As it was partially mentioned in the document above, EDA is going to be the backbone of the serverless approach and entire microservices architecture. You have to start different, change the whole idea you interact with services and functions. Try to imagine two people sitting and play with the ball and we know that they cannot drop the ball otherwise the game will be finished. So they are tight together, we cannot remove one without breaking another, if one becomes sick or something happens it will automatically impact another. Think about it for a second. Now think that these two people are modules of your application, sounds scary to have that tightly coupled architecture, isn’t it? But it pales in comparison with the fact if we increase the amount of player up to 10, 100 or even 1000. Normally your app has definitely more than 2 functions, isn’t it? How can we solve this problem? The obvious answer is microservices because the whole document is about it, but in reality problem will persist if services know about each other and communicate directly. Imagine know that we sit all these players opposite to the wall and put obstacles between each player so they cannot see each. In order to continue playing the have to bounce ball of the wall now. This is essentially what EDA is about. You publish a message to the space which is caught by the subscribed service/lambda. When you do this you do not know how is subscribed to your event, but you can be sure everyone who is will get a message and start processing. It needs to be noted that sometimes even well designed systems have situations when some of those players start to sit in the group because they cannot leave without each other of the specific version etc. In most cases it is related with the breaches in the architecture or specific cases. You have to understand that this is not a my whim this is how distributed systems work. This is all about distributing your loads, services, storages, etc. Certainly, it creates an overhead, but it can be neglected because of the benefits distribution can bring to complex systems which require to manage thousands of services or deal with big data. So it basically works as a circuit breaker which is supposed to protect you from failures and the hell of dependencies. SNS and/or SQS or even the most new AWS EventBridge can be used for that purpose.
- Avoid central centralized repository for your data. This is probably one of the most important aspects of distributed systems. Most of web developers are so inalienably tied up with the idea of central application and central database so they cannot imagine that it can be different. Maybe it should not? Well, the answer is – it depends. Parallel lines are not crossed as we know, but it depends on the mathematics which is used to describe the geometry. The same with the data storage, it depends on the architecture you need. Going back to microservices, it’s paramount aspect. In other words, your entire architecture becomes ultra depend on the data layer which means that it requires you to tremendously redesign your data layer. Certainly, it is not always possible to do in a reasonable amount of time, but by tidying up your services with data lakes you dig your own grave. Your data should start to flow through your system not to sit within central repos. Needless to say, that even with this approach you can end up in having some small data lakes, but at least it will not be data ocean. It is always easier to change, repoint or redirect small data flow rather than migrate or move enormous data lake. It can be one of the hardest problems which need to be resolved but it is essential in building complex, scalable, reliable and easily flexible systems.
- Always design you microservices using DI technique. DI is a programming technique that makes a class independent of its dependencies. It achieves that by decoupling the usage of an object from its creation. The most significant benefit of doing it can be noticed at the stage of implementing unit tests because it allows you to mock dependencies which are not relevant for the test. Besides standard list of benefits, especially in the context of serverless, another benefit of following this technique is that if protects you from being locked by cloud provider. Try to move all your vendor specific services into a separate folder in order to deploy them separately into Lambda Layer, so they will be completely isolated from the microservice package. from By separating your vendor specific SDK services from your business logic you in the case of migration to another cloud provider you will only need to follow LSP and substitute dependencies implementation.
- Always cover your microservices with unit tests. Unit tests are drastically important in software development but its importance is paramount in microservices architecture. Even the fact that microservices architecture decomposes the monolithic application into smaller interdependent services where each service is dedicated for some specific work, unit tests still required. Moreover, they fit perfectly into this model because they require the testing of the most basic functionality of code.
There are a lot of other aspects such as considering costing, the frequency of calls, the efficiency of calls, extra tags, deployment strategies, etc. For example standard message size of SNS/SQS is 64KB, but it supports messages up to 256KB in size, however by sending 256KB message you will be billed for 4 normal SNS/SQS requests. There are similar tricky restrictions for other services such as DynamoDB, API Gateway, S3 etc.
Besides that you should always consider auto-scale factor. The fact that most serverless services have out of the box auto scale doesn’t mean that it will work the same under load. It is significantly important to understand how your application will work under load.
In addition you should always consider drawbacks and restrictions of the existing AWS services and be proactive in reducing problems for the business, your colleagues and yourself. For instance, we know that that AWS console doesn’t allow you to separate your lambda functions by folders, so it is basically a flat list of functions. Considering it, it is essential for developers to follow the same name convention for all lambda functions in order to improve navigation and mitigate problems associated with identification of modules, dependencies, areas, etc. The good name convention should consider microservice name, function name, operation and it uses purpose which means how it is triggered etc. Because lambda functions can be called in response to API request and in response to trigger, so it should also be considered. Think about it from the perspective that you append ‘Controller’ to your controllers in the web application, ‘Service’ to you services, ‘Repository’ to you repositories, etc. In Lambdas it should be similar. I reckon lambdas which are going to be called in response to Api gateway should have name convention as following <ServiceName>_<FunctionName>_<Method>. Internal functions can have a convention using the method or event which triggers them like <ServiceName>_<Event>_<FunctionName>.
Similarly with following name convention you should use Lambda layers for your lambda functions. It is drastically important from the deployment perspective because using them you can configure your Lambda function to pull in additional code form the layers. A layer is a ZIP archive that contains libraries, a custom runtime, or other dependencies. With layers, you can use libraries in your function without needing to include them in your deployment package. It helps to significantly reduce the size of deployment packages and time respectively. There are also limitations for using layers for you functions as well, so basically you cannot use more than 5 layers per function. However, considering that you can create many layers permutations it should not be a problem.
The next one can sound pretty obvious but it needs to be mentioned. Always use versions and aliases for your Lambda functions. It helps easily shift traffic from one version to another in case of deployment or rolling back. Apart of that it allows us to utilize the most efficient deployment automation of serverless code. By having canary deployment in place in place it allows invocation traffic to be routed to the new function versions based on the weight specified. Detailed CloudWatch metrics for the alias and version can be analyzed during the deployment, or other health checks performed, to ensure that the new version is healthy before proceeding.
At the end I would like to highlight the idea which was implicitly mentioned in the SAM section – all serverless code should have a yaml file which will be used for its deployment. It is important to have it, otherwise deployment will be hard.






